How to Build an Enterprise RAG Solution That Actually Works
Enterprise RAG sounds simple on paper: connect documents, retrieve relevant context, send it to an LLM, and return an answer. In practice, that is not what separates a convincing demo from a system a business can trust. A real enterprise RAG solution has to deal with changing data, fragmented tools, access controls, long ingestion pipelines, retrieval quality, observability, and cost. Modern cloud guidance from Microsoft, Google, and AWS all points in the same direction: retrieval quality, hybrid search, metadata, and operational architecture matter just as much as the model itself. (Microsoft Learn)
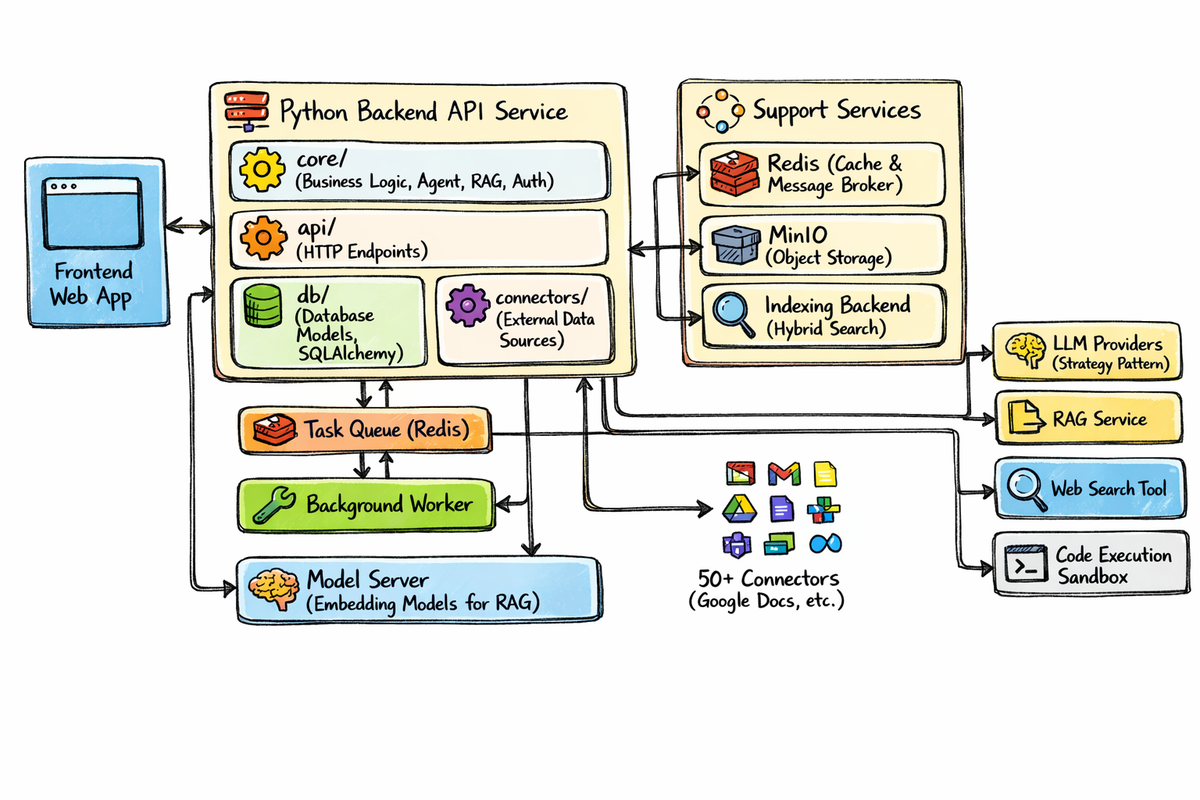
That is why the architecture is the right starting point. It treats RAG as a platform, not a chatbot feature. Instead of putting everything inside one app server, it separates the system into a frontend, a Python backend API, data connectors, a task queue, background workers, object storage, an indexing backend, a model server, and pluggable LLM services. That separation is exactly what helps enterprises scale from one proof of concept to a reusable knowledge system. (Google Cloud Documentation)
Why Most Enterprise RAG Projects Break After the Demo
The most common mistake is thinking enterprise RAG is mainly a model problem. It usually is not. If the wrong chunks are indexed, if permissions are not preserved, if metadata is missing, or if search only works on ideal prompts, even a strong model will produce weak answers. Microsoft’s current RAG guidance emphasizes chunking, structured retrieval, citations, and query pipeline design, while Google’s Vertex guidance highlights hybrid search because semantic retrieval alone often misses exact keywords, identifiers, and business terminology. (Microsoft Learn)
The second mistake is building RAG like a synchronous request-response toy. Enterprise documents arrive from many systems, parsing takes time, re-indexing is ongoing, and embedding pipelines need retries and version control. That is why the architecture’s task queue, background worker, and object storage layers are not optional extras. They are part of what makes the system dependable. (Google Cloud Documentation)
What Makes a RAG Solution Enterprise-Grade
An enterprise-grade RAG solution does four things well.
First, it grounds responses in private enterprise knowledge. That is the core purpose of RAG: improve answer relevance and accuracy by combining retrieval with generation over proprietary data. (Google Cloud)
Second, it uses retrieval methods that match real business content. Hybrid retrieval is especially important because enterprises do not search only for ideas. They search for account IDs, policy names, product codes, contract clauses, error strings, and internal acronyms. Keyword and semantic retrieval work better together than either one alone in many enterprise settings. (Google Cloud Documentation)
Third, it respects governance. Metadata filtering, permission-aware access, and tenant boundaries are essential. AWS documentation for knowledge retrieval makes this especially clear through metadata-based filtering and reranking controls, which are central to keeping results relevant and scoped correctly. (AWS 文档)
Fourth, it is operationally maintainable. Enterprises need repeatable ingestion, durable storage, reprocessing, monitoring, and the ability to improve retrieval without rewriting the whole stack. That is why strong RAG systems are modular by design. (Google Cloud Documentation)
The Architecture: A Practical Blueprint for Enterprise RAG
On the left is the Frontend Web App, where users ask questions, review answers, inspect sources, and provide feedback. In the middle is the Python Backend API Service, which acts as the orchestration layer and contains the business logic, agent logic, auth, API endpoints, database access, and connectors. Below that are the Task Queue and Background Worker, which take care of asynchronous ingestion and indexing work. Supporting services include Redis, MinIO, and an Indexing Backend for hybrid search. On the right are pluggable LLM Providers, a dedicated RAG Service, optional external tools like Web Search, and a Code Execution Sandbox. It is a clean separation of concerns, and that is exactly what enterprises need.
Frontend Web App: Where Trust Is Won or Lost
The frontend is not just a chat box. In enterprise RAG, the user experience should prove that the answer is grounded. That means citations, source snippets, document titles, timestamps, and permission-safe previews should be visible. Users should be able to understand where an answer came from and whether they should trust it.
A good enterprise frontend also supports follow-up questions, conversation history, feedback signals, and sometimes document drill-down. When an answer is weak, the UI should make that visible instead of hiding uncertainty behind confident wording. This is especially important because grounded generation is valuable only when users can verify the grounding.
Python Backend API Service: The Real Control Tower
The Python backend is the most important part of the architecture. It is where enterprise logic lives. The frontend should never directly talk to all your models, indexes, and external systems. The backend should manage that complexity.
In the structure, the core/ layer is where the business logic belongs: auth, RAG orchestration, context building, answer formatting, provider routing, and agent behaviors if you add them later. The api/ layer exposes clean HTTP endpoints. The db/ layer stores application data, connector state, user sessions, audit records, and document metadata. The connectors/ layer handles enterprise data sources. This kind of modular design makes the platform easier to test, easier to scale, and much safer to evolve.
This also gives you a clean place to enforce role-based access and tenant-aware retrieval before any generation happens. That one design decision can prevent a huge class of enterprise failures.
Database Layer: More Than Just App State
A lot of teams obsess over vector databases and underestimate relational data. In enterprise RAG, the regular database is where operational truth lives. It should store users, roles, permissions, connector states, sync history, ingestion jobs, chunk metadata references, document ownership, and chat records.
Why does that matter? Because metadata is not a side detail. Metadata powers filtering, routing, freshness controls, and access-aware retrieval. AWS’s current guidance on knowledge bases explicitly emphasizes metadata association and filtering because retrieval quality improves when the system can narrow the search space intelligently. (AWS)
In other words, if embeddings help you find meaning, metadata helps you find the right meaning for the right user.
Connectors: The Gateway to Real Enterprise Knowledge
Most enterprise knowledge is scattered across tools. It lives in Google Docs, shared drives, internal wikis, PDFs, ticketing systems, CRM notes, email threads, and collaboration apps. That is why connectors are a first-class architectural concern.
A good connector layer should support scheduled sync, incremental updates, change detection, retry logic, and metadata normalization. It should also preserve source-level permissions whenever possible. If your system pulls content from many apps but loses ownership and access context during ingestion, you create risk immediately.
This is one of the biggest differences between a serious RAG platform and a weekend prototype. Prototypes index a folder. Enterprise platforms build a repeatable ingestion framework.
Task Queue and Background Worker: The Hidden Backbone
One of the strongest ideas in the architecture is using Redis both as cache and message broker, plus a dedicated task queue and background worker. That design is practical because ingestion is naturally asynchronous.
When new files arrive, the system may need to download the asset, store the original, parse it, run OCR if needed, extract text, chunk it, attach metadata, generate embeddings, and update the hybrid search index. None of that should happen inside a user-facing request. It belongs in the queue.
This is where background workers earn their place. They make ingestion more reliable, isolate heavy workloads, enable retries, and let the platform scale indexing independently from query traffic. That is how you avoid turning a good search product into a latency problem.
MinIO or Object Storage: The System of Record for Raw Content
Enterprises should keep original files and processing artifacts in object storage. In the diagram, MinIO plays that role. This is important for durability, traceability, and reprocessing.
When chunking improves, when a better parser is introduced, or when compliance needs an audit trail, you want the original source asset available. Object storage is also a smart place to keep OCR outputs, extracted text, chunk manifests, and ingestion logs. Cloud reference architectures consistently treat storage as a foundational part of RAG pipelines because retrieval quality often depends on your ability to re-run and improve document processing over time. (Google Cloud Documentation)
Indexing Backend: Why Hybrid Search Should Be the Default
the diagram calls out Hybrid Search, and that is exactly right for enterprise use cases.
Vector search is excellent for semantic similarity. It helps find conceptually related content, even when wording differs. But enterprises also need lexical precision. Exact product names, IDs, policy codes, legal phrases, log strings, and abbreviations do not always behave well in vector-only search. Google’s Vertex AI documentation explicitly describes hybrid search as the combination of semantic and token-based retrieval to improve overall search quality. Microsoft’s Azure AI Search guidance likewise highlights hybrid search and structured retrieval choices in modern RAG systems. (Microsoft Learn)
That is why a strong enterprise indexing backend should support:
- vector retrieval
- keyword retrieval
- metadata filtering
- reranking
- source attribution
If retrieval is weak, generation cannot save it. Better answers begin with better candidates.
Model Server: A Dedicated Embedding Layer Matters
The Model Server in the architecture is responsible for embedding generation for RAG. That separation is smart because embedding workloads are different from generation workloads.
Embeddings often run in bulk during ingestion, may need batching, and can change independently of the chat model you use for answers. If you tie them too closely together, upgrades become painful. Keeping a dedicated model service also makes versioning easier. If you roll out a new embedding model and retrieval gets worse, you want rollback options, controlled migration, and measurable A/B evaluation.
AWS guidance on chunking and retrieval also reinforces that chunking strategy and retrieval configuration strongly influence downstream performance, so treating embeddings and indexing as their own subsystem is the right mindset. (AWS)
RAG Service: Where Retrieval Becomes Grounded Generation
The RAG Service is where your platform turns search results into an answer. This layer should take a user query, apply auth and filters, retrieve candidate chunks, rerank them, build context, and then send a grounded prompt to the selected LLM provider.
This is also the right place for query rewriting, answer formatting, citation generation, and fallback logic. Microsoft’s current guidance distinguishes classic RAG from more agentic retrieval approaches, but in both cases the central goal is the same: improve accuracy by grounding the model in indexed knowledge and exposing useful citation details. (Microsoft Learn)
In an enterprise setting, the RAG service should not just answer questions. It should answer them in a way that is inspectable, permission-safe, and consistent.
LLM Providers: Use a Strategy Pattern, Not a Hard Dependency
the diagram shows LLM Providers (Strategy Pattern), and that is a strong architectural choice. Enterprises should avoid hard-coding one provider into the business logic.
Different workloads need different tradeoffs. Some tasks favor lower latency. Some need stronger reasoning. Some need regional deployment flexibility. Some need cost control. A provider abstraction makes it much easier to route requests intelligently, compare results, and change providers later without rewriting the whole application.
This also reduces long-term lock-in. Enterprise AI stacks evolve quickly, and model strategy is one of the parts most likely to change.
Optional Tools: Web Search and Code Execution
The architecture also includes a Web Search Tool and a Code Execution Sandbox. These are not necessary for every RAG system, but they can dramatically expand capability.
Web search is useful when freshness matters or when internal documents are not enough. Code execution is useful when the answer requires calculations, table transformation, file generation, or structured analysis. The important thing is control. Sandboxing, logging, policy enforcement, and permission checks are essential. Optional tools should make the system more useful, not less governable.
The End-to-End Flow of an Enterprise RAG Platform
A clean enterprise RAG flow looks like this.
First, connectors pull content from enterprise systems. New or changed items are detected and sent to the task queue.
Second, the background worker fetches the source files and stores originals in object storage. It parses the content, extracts text, collects metadata, and prepares the document for indexing.
Third, the system chunks the content and generates embeddings through the model server. Chunking matters a lot here. AWS’s current documentation highlights semantic chunking as a way to improve retrieval quality by splitting content into more meaningful units. (AWS)
Fourth, the indexing backend stores the chunks for hybrid search, along with metadata filters and references back to the original document.
Fifth, when a user asks a question, the backend authenticates the request, checks permissions, and passes the query to the RAG service.
Sixth, the RAG service retrieves relevant chunks using hybrid search, applies metadata filters, possibly reranks the results, and builds a compact grounded context.
Seventh, the selected LLM generates an answer based on that context, and the frontend shows the answer with citations and source traces.
Eighth, the platform logs the interaction, captures feedback, and feeds the results into evaluation and improvement loops.
That full cycle is what makes the solution enterprise-grade. It is not one smart prompt. It is a managed knowledge pipeline.
Security, Governance, and Compliance Cannot Be Added Later
Security in enterprise RAG starts before generation. Retrieval itself must be permission-aware. A user should never retrieve chunks from a document they are not allowed to access. Guardrails applied only at the model stage are not enough. AWS notes that runtime guardrails do not automatically govern the references retrieved from a knowledge base, which is a useful reminder that retrieval controls and access controls must be designed directly into the system. (AWS)
Auditability matters too. Enterprises should log queries, retrieval events, source usage, model choices, and workflow outcomes. That helps with debugging, compliance, and trust. It also makes evaluation possible. If you do not know which chunks were retrieved and why, you cannot improve the RAG stack in a disciplined way.
What Most Teams Still Get Wrong
They over-focus on the LLM and underinvest in retrieval.
They ignore metadata.
They skip evaluation.
They treat ingestion as a one-time import instead of a continuous pipeline.
And they forget that RAG in a real business has to survive changing content, changing permissions, and changing expectations.
The companies that do this well build RAG as reusable infrastructure. The ones that struggle usually build a chatbot first and only later realize they needed a platform.
Best Practices for Building an Enterprise RAG Solution
Start with one high-value use case, not ten. Internal knowledge search, support enablement, policy lookup, and sales enablement are all good starting points.
Design ingestion and retrieval as reusable services. That way, one successful implementation becomes the base for more teams.
Default to hybrid search unless you have a strong reason not to. Current vendor guidance across major platforms points toward combining lexical and semantic retrieval for better practical search quality. (Microsoft Learn)
Invest in metadata design early. Metadata helps with filtering, security, precision, and evaluation.
Version the embedding pipeline. Retrieval changes should be measurable and reversible.
Treat observability as part of the product. Log retrieval, reranking, prompt assembly, answer generation, and user feedback.
And keep the architecture modular. A modular stack lets you swap providers, improve parsers, test ranking strategies, and evolve without tearing everything down.
Final Thoughts
The best enterprise RAG solution is not the one with the most impressive demo. It is the one that keeps working when data grows, permissions get complicated, and the business starts relying on it.
That is why the architecture in the image is strong. It separates the system into the right layers: frontend experience, backend orchestration, connectors, queue-driven ingestion, durable storage, hybrid retrieval, embedding infrastructure, grounded generation, and pluggable model providers. It is the kind of design that gives enterprises room to scale, room to govern, and room to improve.
If you want enterprise RAG to succeed, start with architecture first and model choice second. In the long run, that is what turns a clever assistant into a trusted business system. (Google Cloud Documentation)